.png)
Python爬虫是否必须使用代理IP 合理选择才是关键

在学习和使用 Python 爬虫的过程中,很多初学者都会形成一种固定认知:只要进行数据抓取,就必须配合代理 IP 使用,否则很快就会被网站限制访问。事实上,这种理解并不完全准确。是否需要使用代理 IP,应当结合具体的抓取规模、访问频率以及目标网站的防护策略来综合判断。
从本质上看,爬虫程序与普通用户访问网站并没有根本区别。无论是浏览器还是爬虫,最终都是向服务器发送 HTTP 请求并接收响应数据。差异在于访问行为的特征。普通用户的访问频率较低,操作具有随机性,而爬虫往往在短时间内连续请求大量页面,这种高频、规律性的访问行为更容易触发服务器的风控机制。
如果抓取任务本身规模较小,例如只需要采集某个网站的少量页面或上百篇文章,并且在程序中合理控制请求频率,适当设置延时,模拟正常用户的访问节奏,那么在不使用代理 IP 的情况下,依然可以顺利完成任务。许多网站的基础防护策略主要针对异常高频访问,对于这种温和的抓取行为通常不会立即限制。
但当抓取需求发生变化时,情况就会有所不同。如果需要采集的数据量较大,例如成千上万条内容,或者涉及多线程、高并发、分布式抓取场景,单一 IP 很容易被识别为异常来源。一旦访问频率超出服务器允许范围,就可能出现访问受限、验证码验证甚至直接封禁 IP 的情况。这也是代理 IP 在爬虫项目中被频繁使用的主要原因。
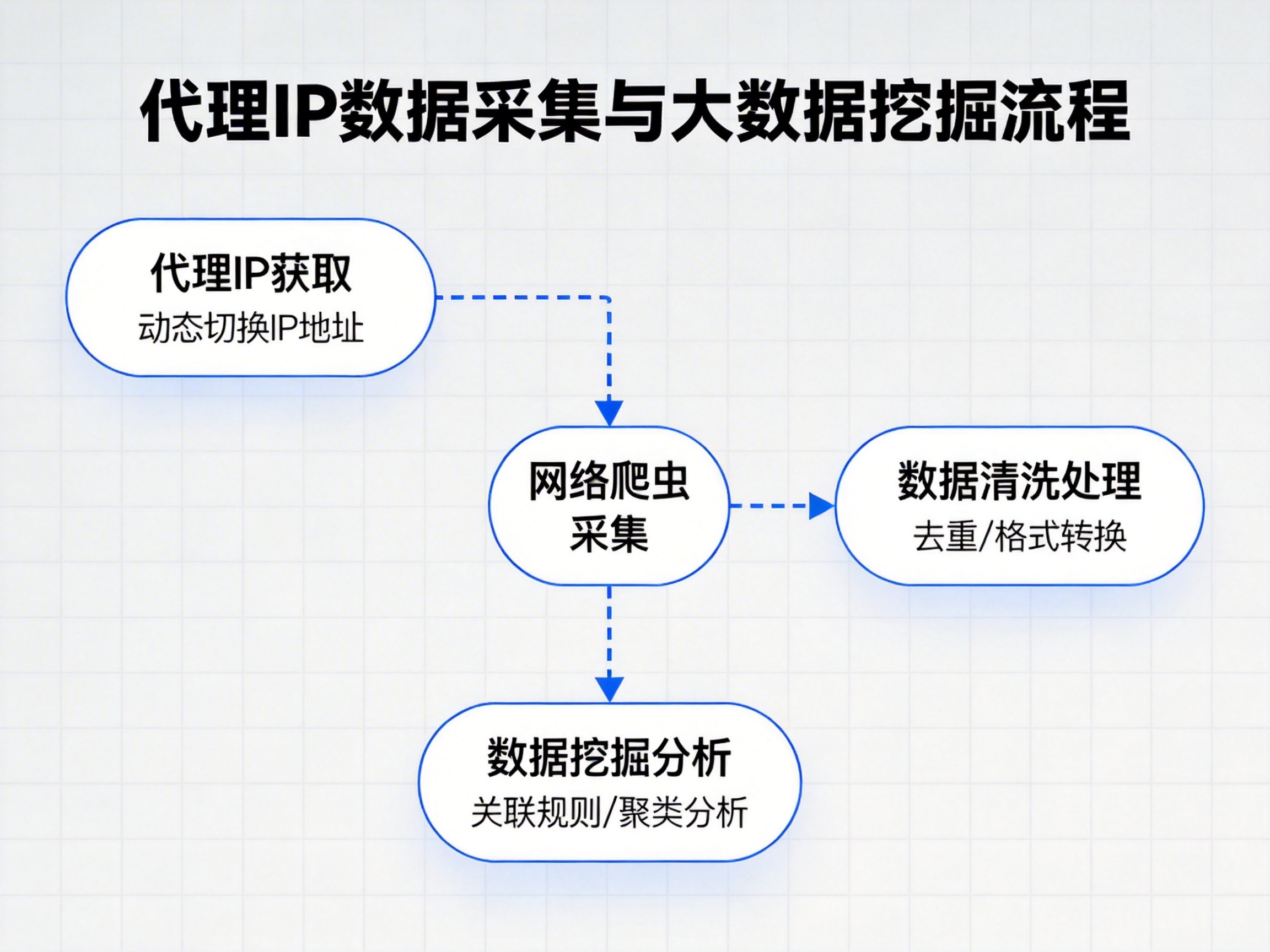
代理 IP 的核心作用在于分散访问压力。通过不断更换出口 IP,可以将大量请求分布到不同网络节点,从而降低单个 IP 的访问频率,减少被识别和限制的风险。在实际项目中,许多中大型爬虫任务都会结合代理 IP 池来运行,以确保抓取过程的连续性和稳定性。
需要注意的是,是否使用代理 IP 并不是判断爬虫能力高低的标准,而是一种策略选择。合理的请求控制、完善的异常处理机制以及对目标网站规则的理解,同样是爬虫开发中不可忽视的因素。盲目堆叠代理资源,反而可能增加成本和系统复杂度。
在实际应用中,建议根据任务规模进行判断。小规模、低频率的数据抓取,可以优先通过优化程序逻辑来完成;而在高并发、大数据量采集场景下,代理 IP 则是应对反爬机制的重要手段。选择稳定、可靠的代理服务,有助于提升整体抓取效率,确保项目顺利推进。
zhyun
暂无介绍....