.png)
大模型时代的语料采集:中海云算代理IP如何构建AI训练的数据底座?

在人工智能技术日新月异的当下,大语言模型(LLM)的进化速度很大程度上取决于底层训练数据的规模与质量。高质量、多维度的语料库是提升模型逻辑推理、语义理解及多语言处理能力的核心资源。然而,面对海量的互联网公开数据,如何在确保高效、合规的前提下完成大规模抓取,成为各大AI科研机构与企业面临的技术瓶颈。中海云算作为专业的大数据基础能力服务商,通过提供高性能的代理IP资源,正成为构建AI训练数据底座的关键基础设施。
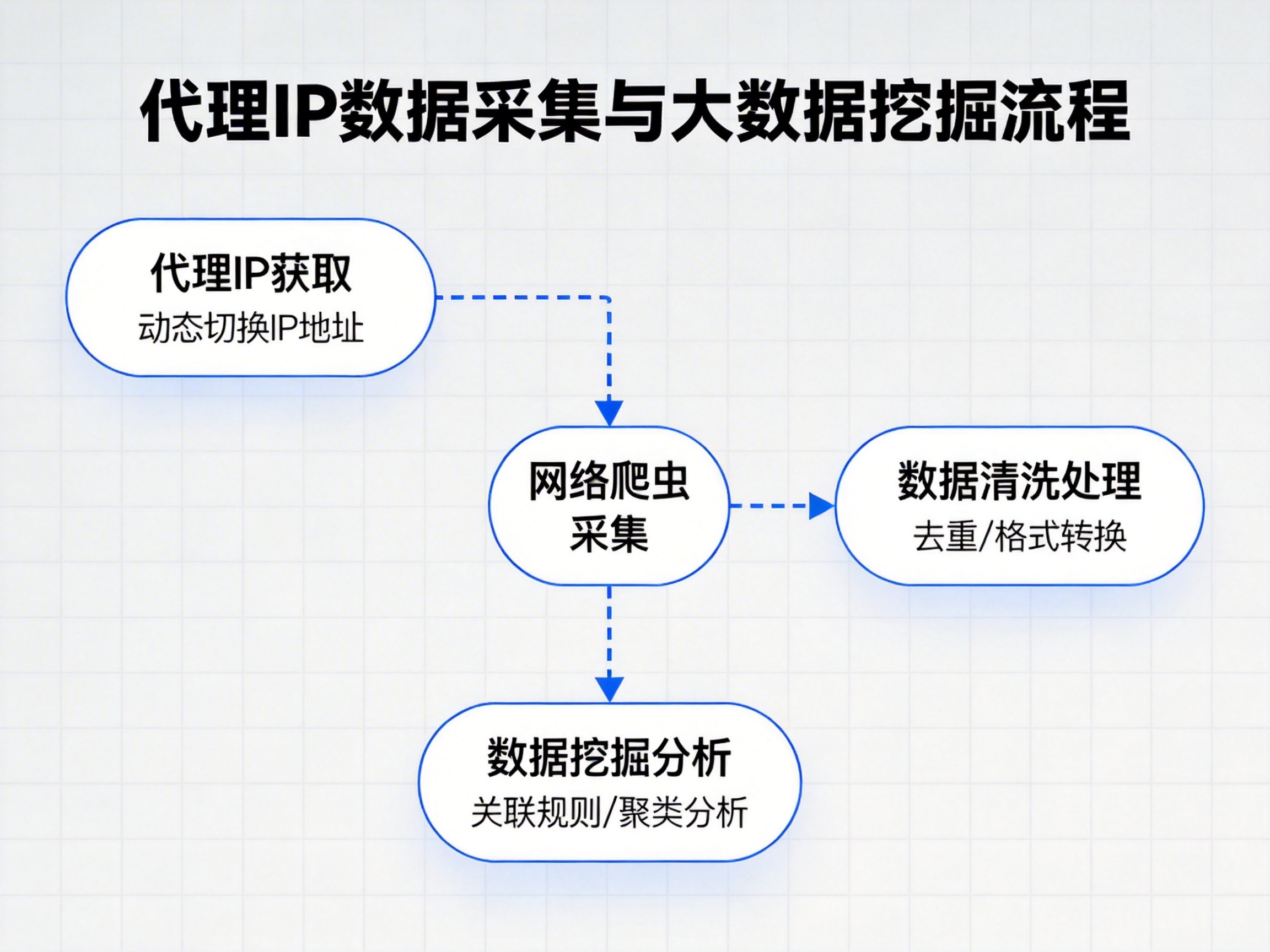
大模型训练对数据的需求是海量的,且通常具有极高的时效性。在构建语料库的过程中,采集系统需要频繁访问各类新闻门户、社交平台、学术期刊及专业论坛。然而,这些高质量数据源普遍设有严密的频率限制与反爬机制。如果使用单一或少量的固定IP进行访问,极易触发防火墙保护,导致采集链路中断。中海云算提供的动态短效代理与隧道代理方案,通过覆盖全国200多个城市、日流水超600万的纯净IP池,使采集系统能够模拟数以万计的真实终端并发访问。这种分布式采集模式不仅规避了IP封禁风险,更极大地提升了语料获取的吞吐量,为模型迭代赢得了宝贵的时间。
除了数据规模,语料的多样性与地域性对于提升模型的文化适应性至关重要。自然语言处理(NLP)模型需要理解不同方言、语境以及特定地域的社会背景。中海云算的边缘网络节点分布极其广泛,能够为AI企业提供具备精准地理位置属性的访问出口。通过调用不同省份和城市的代理IP,模型训练者可以获取到最真实、最本土化的搜索结果与社交媒体讨论。这种基于地理位置的细分数据采集,能够有效弥补训练集在跨文化语义理解上的短板,让大模型在处理特定区域业务时表现出更强的人性化与精准度。
在采集过程中,系统的稳定性与匿名性直接关系到研发投入的安全性。人工智能研发通常伴随着巨大的算力与人力成本,任何环节的停滞都可能造成损失。中海云算的代理IP技术采用高匿名转发机制,在请求过程中完整隐匿了客户端的真实特征,确保采集行为在合理的合规框架内运行。同时,中海云算的底层架构针对高并发场景进行了深度优化,毫秒级的响应延迟与极高的请求成功率,确保了数据传输通道的稳健。即便在目标平台加强风控的特殊时段,中海云算也能通过动态清洗与资源调配,保障采集任务的平滑进行。
数据安全与合规性也是AI时代不可逾越的红线。中海云算在提供代理服务的过程中,严格遵守法律法规,协助企业建立合规的数据获取规范。通过中海云算提供的API接口,开发者可以精准控制采集频率、设定请求头逻辑,从而在获取公开数据的同时,最大程度减少对目标站点的压力负载,达成一种生态平衡的数据交互模式。这种专业的技术姿态,为人工智能的持续演进提供了源源不断的动力,也让数据要素真正成为驱动AI创新的核心生产力。
zhyun
暂无介绍....