.png)
AI大模型训练数据采集中的代理IP应用策略

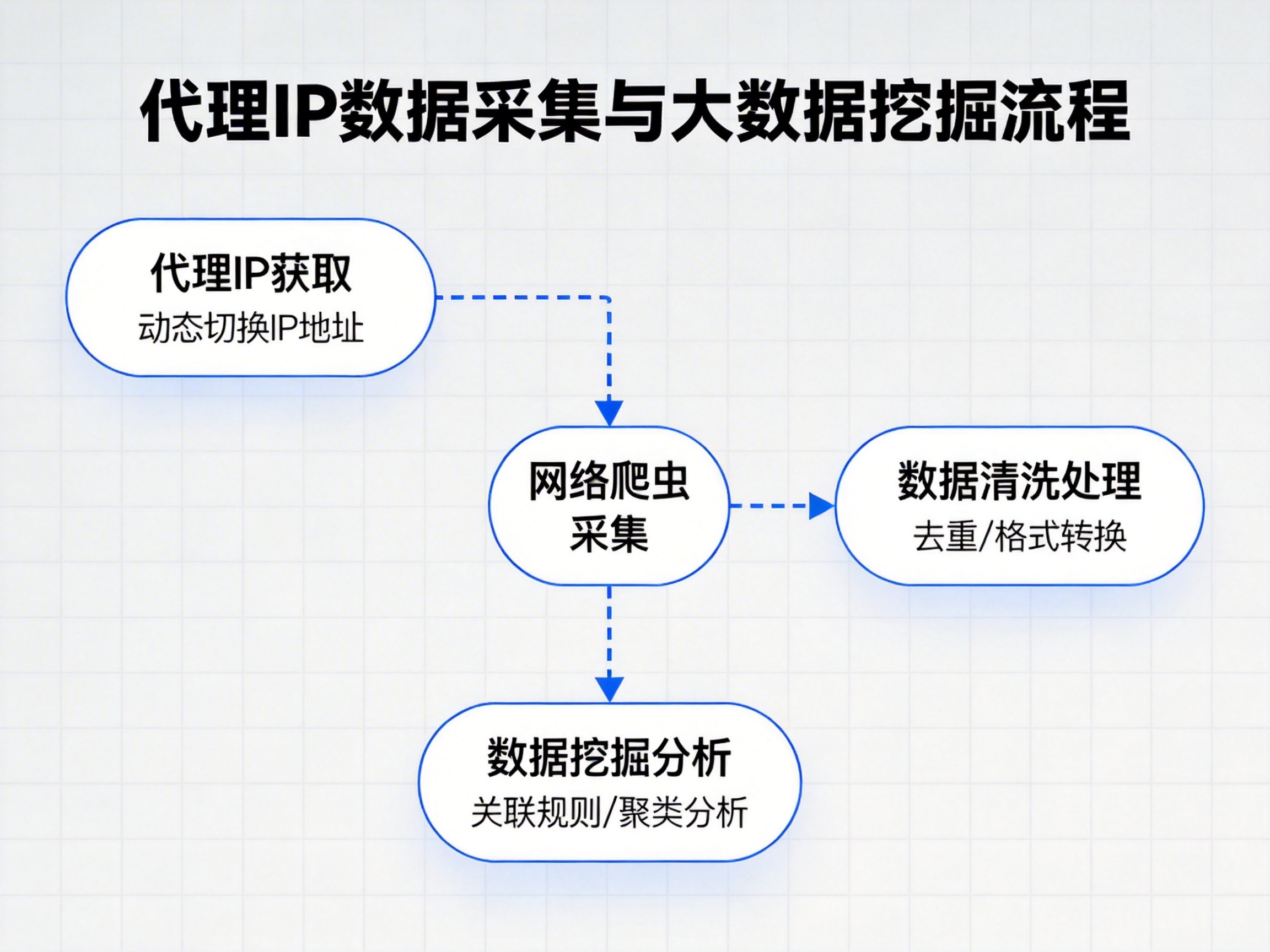
随着ChatGPT、Claude等大语言模型的爆发式增长,AI训练数据的获取成为科技行业的关键议题。大模型训练需要海量的高质量文本数据,而互联网公开数据是最重要的来源之一。代理IP技术在AI大模型的数据采集过程中发挥着不可或缺的作用,通过IP轮换和地域分布,为数据采集提供了稳定的技术支撑。中海云算等专业代理服务商已经为多家AI头部企业提供了优质的数据采集代理解决方案。
AI大模型对训练数据的需求具有规模大、来源广、时效强的特点。单一IP地址在采集海量网络数据时,极易触发目标网站的反爬机制,导致IP被封禁或访问受限。代理IP通过智能轮换机制,为每次请求分配不同的IP地址,有效规避了这一风险。同时,代理服务商通常拥有覆盖全国各地的IP资源,能够实现地域化的数据采集,获取不同地区、不同网络环境下的用户生成内容,为AI模型的泛化能力提供保障。
在数据采集的合规性方面,代理IP技术也发挥着重要作用。通过匿名访问,保护了数据采集方的身份信息,降低了数据采集过程中的法律风险。AI企业在使用代理IP进行数据采集时,需要建立完善的合规体系,确保采集行为符合相关法律法规要求。中海云算等服务商具备完善的合规资质,包括互联网虚拟专用网业务许可证等多项认证,为AI企业的数据采集活动提供合规保障。
选择适合AI大模型训练的代理IP服务需要重点评估几个方面。高并发能力是首要考量,AI数据采集通常是大规模、高并发的访问任务,代理服务器需要具备处理海量并发请求的能力。低延迟也很重要,数据采集的速度直接影响模型训练的进度,低延迟的代理能够显著提升采集效率。此外,IP资源的丰富度和地域覆盖范围也是重要指标,覆盖全国主要城市的IP资源能够为AI训练提供更加多样化的数据来源。
zhyun
暂无介绍....