.png)
Python爬虫如何使用代理IP高效采集数据?一文掌握核心技巧

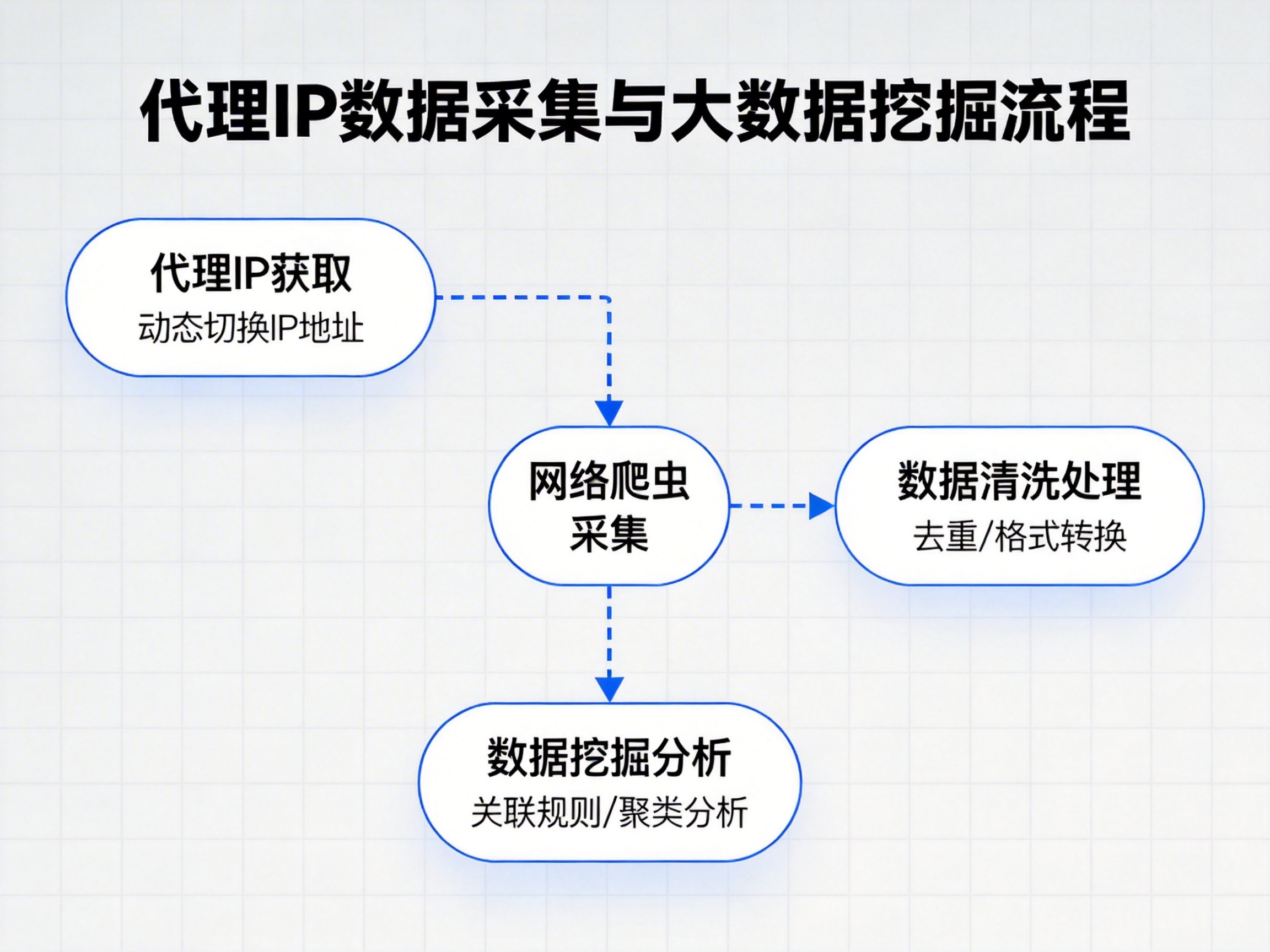
在网络数据采集的实际操作中,Python爬虫因其灵活、高效、易扩展而被广泛应用。然而,随着目标网站反爬机制的升级,单一IP频繁访问往往会导致封禁或限速问题。此时,代理IP的应用成为解决访问限制、提高采集效率的重要手段。本文将详细介绍Python爬虫中代理IP的原理、分类与使用方法,帮助你构建更稳定的采集环境。
一、代理IP在Python爬虫中的作用
代理IP是指通过代理服务器中转请求,让爬虫程序的访问流量以代理IP的身份出现,而非真实设备IP。这种机制不仅能有效隐藏身份,还能实现多点分布式访问。其主要作用包括:
- 突破IP封锁:网站会限制单一IP的访问频率,而代理IP可模拟不同访问来源,避免因高频请求导致封禁。
- 提升数据采集效率:结合并发与多IP切换,可以在保持访问稳定的同时提升抓取速度。
- 增强隐私与安全:通过中转机制防止真实IP泄露,降低因访问痕迹被跟踪而带来的风险。
二、常见的代理IP类型与应用场景
根据使用需求与访问特性,Python爬虫常用的代理IP可分为以下几类:
1. 静态代理IP
静态代理IP在一定时间内保持固定不变,适合需要持续会话或长连接任务,如账号登录验证、订单监测等。
2. 动态代理IP
动态代理会周期性更换IP地址,适合高频、大规模采集任务。例如电商商品监控、新闻数据抓取等,使用动态代理能显著降低被识别的风险。
3. 公共代理与独享代理
公共代理IP价格低廉甚至免费,但使用人数众多、稳定性差。独享代理IP则由服务商提供,IP纯净度高、不与他人共享,适合企业级项目使用。
在众多服务商中,中海云算凭借稳定的网络结构与丰富的资源池,提供HTTP、HTTPS、SOCKS5等多种代理协议,IP覆盖全球200多个城市,可用率高达99.9%,长期保持业内领先水平。
三、在Python中配置代理IP的方法
Python中最常用的HTTP请求库为requests和Scrapy框架,下面是它们的代理IP配置方法。
1. requests库配置示例
import requests
proxies = {
'http': 'http://username:password@proxy_ip:proxy_port',
'https': 'http://username:password@proxy_ip:proxy_port',
}
url = "http://httpbin.org/ip"
response = requests.get(url, proxies=proxies)
print(response.json())
通过定义proxies字典即可为请求添加代理配置,实现访问IP切换。
2. Scrapy框架配置示例
在Scrapy中,通过中间件机制配置代理更为灵活,可实现自动切换:
# settings.py
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
'my_project.middlewares.ProxyMiddleware': 100,
}
# middlewares.py
class ProxyMiddleware:
def process_request(self, request, spider):
request.meta['proxy'] = 'http://username:password@proxy_ip:proxy_port'
这种方式能确保在不同请求中动态加载代理,适用于分布式采集环境。
四、动态代理IP的自动切换实践
在大规模爬取任务中,手动切换IP效率较低。通过调用代理服务商的API,可以实现自动化代理轮换。中海云算支持实时获取最新代理IP接口,以下是简单的示例:
import requests, time
def fetch_proxy():
# 示例:通过API获取中海云算的动态代理
return {
'http': 'http://username:password@dynamic_ip:port',
'https': 'http://username:password@dynamic_ip:port',
}
url = "http://example.com"
for _ in range(5):
proxies = fetch_proxy()
response = requests.get(url, proxies=proxies)
print(f"Response: {response.status_code}")
time.sleep(5)
这种方式可以在每次请求后自动更新代理,大幅提升爬取的成功率和可用性。
五、提升Python爬虫代理稳定性的技巧
- 控制访问频率:避免连续高频访问同一网站,可设置合理延时。
- 维护代理池:剔除失效IP,定期更新代理池,保证整体健康度。
- 支持多协议代理:优先选择兼容HTTP、HTTPS与SOCKS5的服务商,以增强传输加密与隐私保护。
凭借全球化节点资源与高可用代理技术,中海云算为企业与开发者提供了高纯净、高匿名、高成功率的代理IP解决方案,助力Python爬虫稳定高效地采集各类数据。
zhyun
暂无介绍....