.png)
AI时代如何利用代理IP提升大模型训练与应用效率

随着人工智能技术的持续演进,大模型已成为推动智能应用落地的重要基础。在模型训练、推理和持续优化过程中,数据规模、数据质量以及获取效率,直接影响最终效果。为了在复杂网络环境中高效获取数据,代理IP逐渐被引入到大模型相关的技术体系中,成为提升整体效率的重要辅助手段。
代理IP是一种通过中间服务器转发网络请求的技术方式。当请求经由代理服务器发送时,对外呈现的是代理服务器的IP地址,而非用户真实IP。根据使用方式不同,代理IP通常分为静态代理和动态代理。静态代理IP相对固定,适合稳定访问场景;动态代理IP会定期轮换,更适合高频访问和大规模数据采集需求。
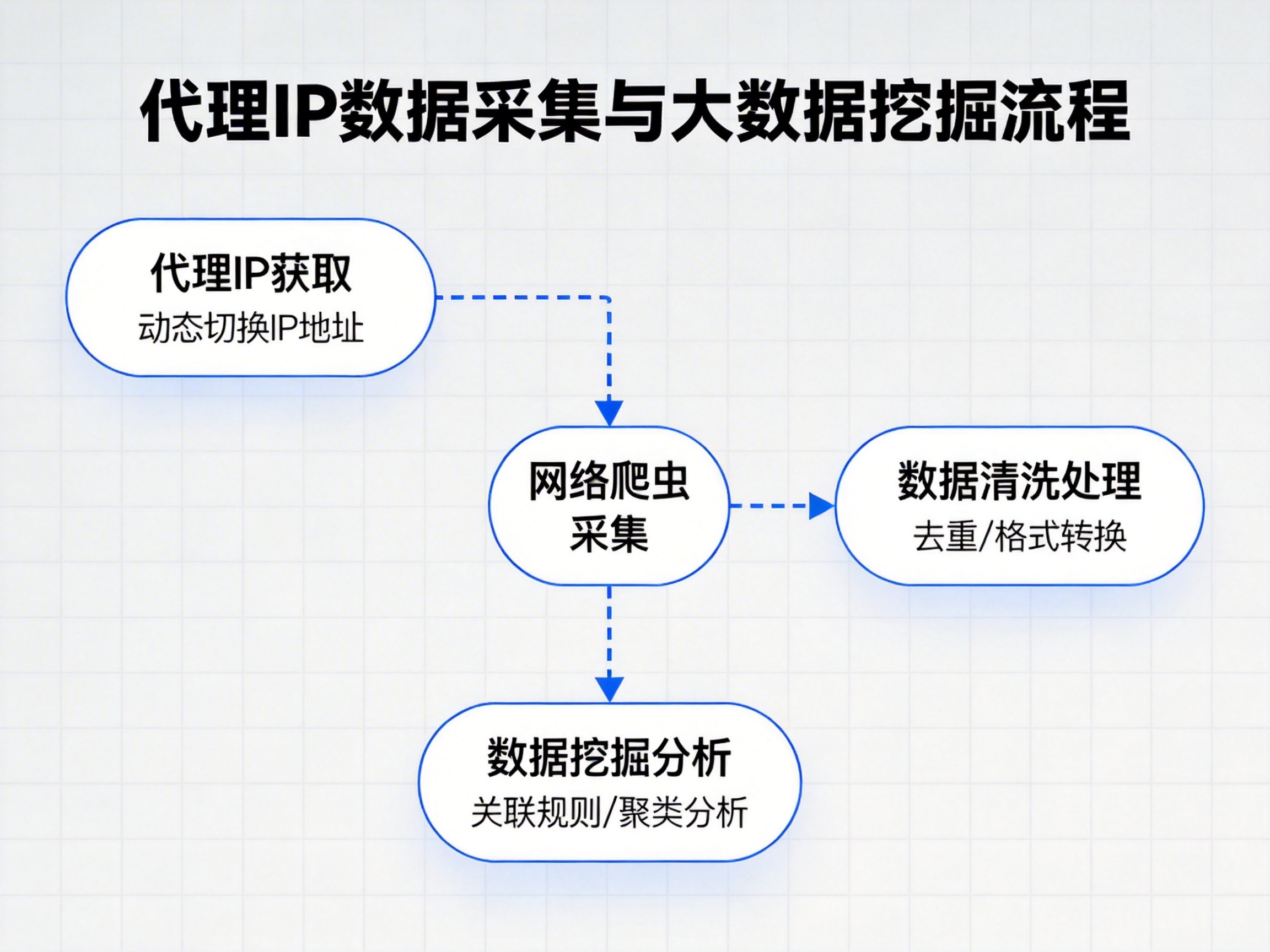
从工作机制来看,代理IP主要通过请求转发实现访问控制。用户请求先发送至代理服务器,由代理服务器替换IP信息后再访问目标站点,返回结果再经代理转交给用户。这一过程不仅增强了访问灵活性,也为批量化、自动化操作提供了条件。
在大模型训练过程中,代理IP的首要价值体现在数据采集效率上。模型训练往往依赖海量公开数据,而直接使用单一IP进行高频抓取,极易触发访问限制。通过代理IP分散请求来源,可以在保证访问稳定性的前提下,提高单位时间内的数据获取量,为模型训练提供充足的数据支持。
数据多样性同样是影响模型效果的重要因素。借助不同地区、不同网络环境的代理IP,可以模拟多种真实访问场景,获取更加多元的数据样本。这对于提升大模型在实际应用中的泛化能力和适应能力具有积极意义,尤其适用于语言模型、推荐系统等对数据覆盖面要求较高的场景。
在实际应用中,地理限制也是数据获取过程中的常见问题。部分数据源仅对特定区域开放,通过代理IP模拟对应地区访问,可以在合规前提下获取相关数据,满足跨区域分析和业务研究需求。这对面向多市场布局的企业尤为重要。
代理IP还能够有效降低封禁风险。在持续抓取或接口调用过程中,通过IP轮换策略,即便个别IP出现异常,也不会影响整体任务执行,从而提升大模型训练与更新过程的连续性。
为了充分发挥代理IP的价值,合理选择与管理尤为关键。优质的代理服务应具备良好的稳定性、较低的访问延迟以及充足的IP资源覆盖。同时,在实际使用中,应根据目标网站特性制定访问策略,并对代理IP状态进行持续监控,及时更新失效资源。
需要注意的是,代理IP的使用应建立在合法合规基础之上。在数据采集和模型训练过程中,应遵循相关法律法规及平台规则,避免涉及敏感信息和违规行为,确保技术应用的可持续性。
在AI技术不断深入发展的背景下,代理IP已逐步成为支撑大模型高效运行的重要工具之一,为数据获取与模型优化提供了更具弹性的技术空间。
zhyun
暂无介绍....