.png)
HTTP代理在爬虫业务中的作用与实践应用解析

HTTP代理是一种常见的网络中转服务,在客户端与目标服务器之间起到桥梁作用。用户的访问请求并不会直接到达目标网站,而是先发送至代理服务器,再由代理服务器完成转发并返回结果。在这一过程中,目标网站只能识别代理服务器的IP地址,从而实现对真实IP的隐藏。这种访问方式不仅有助于降低带宽消耗,还能在一定程度上提升访问稳定性与隐私安全性。
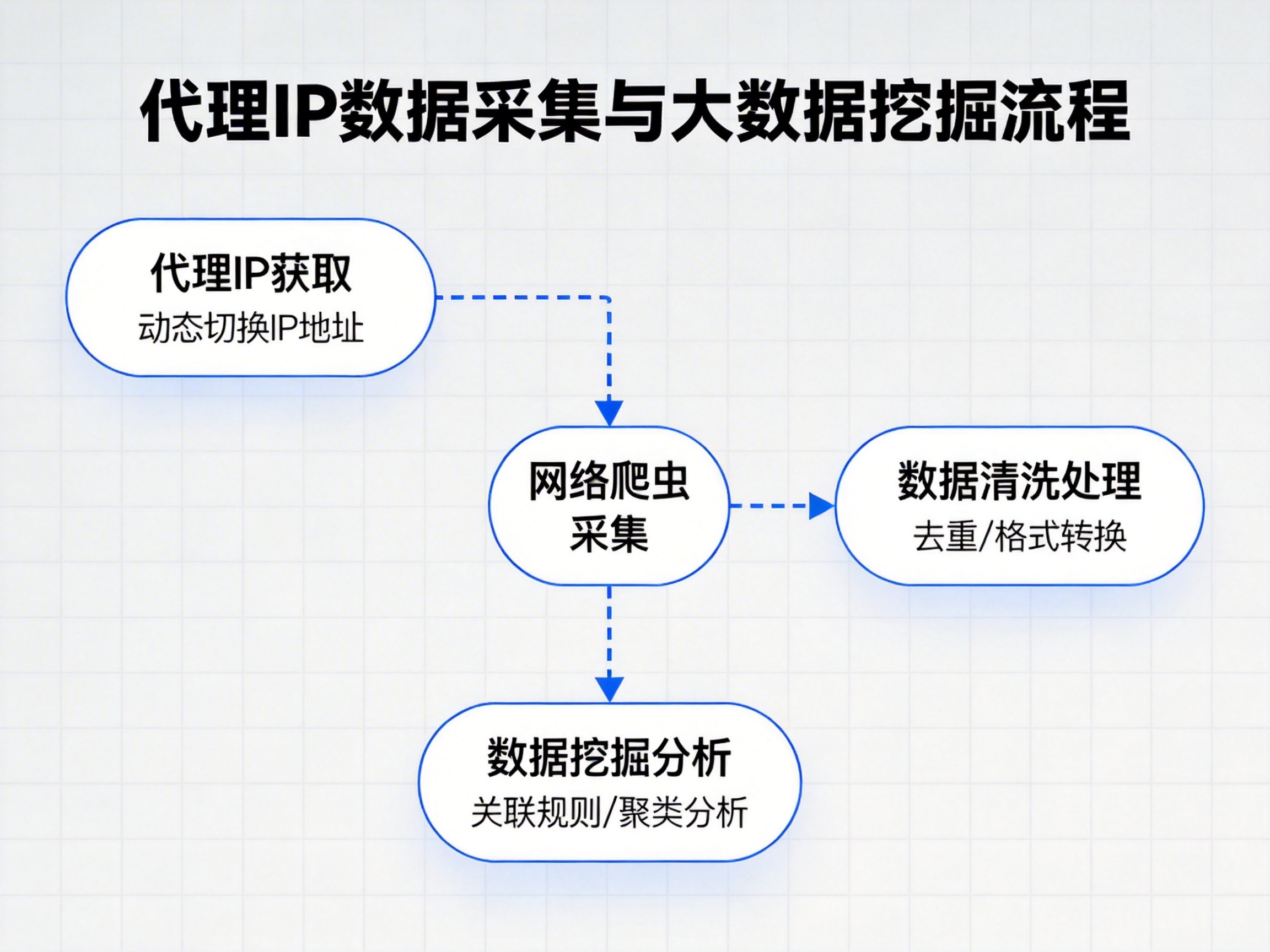
在数据采集和爬虫业务中,HTTP代理几乎是不可或缺的基础资源。随着网站防护机制不断升级,频繁的自动化访问极易触发风控规则,导致IP被限制甚至封禁。通过合理使用HTTP代理,可以有效分散请求来源,降低单一IP的访问压力,从而保障爬虫任务的连续执行。
规避IP封禁是HTTP代理最核心的价值之一。当爬虫程序需要高频访问目标网站时,代理IP可以按策略进行切换,避免请求集中在同一个地址上,大幅提升整体抓取成功率。对于需要长时间运行的数据采集任务,这一点尤为关键。
在多区域数据采集方面,HTTP代理同样具有明显优势。部分网站会根据访问者所在地区返回不同内容,例如电商价格、促销信息或展示规则。借助分布在不同地区的代理服务器,爬虫可以模拟多地域用户访问环境,获取更加全面、真实的数据,为市场分析和决策提供参考。
从隐私与安全角度来看,HTTP代理能够有效降低真实身份暴露的风险。在爬虫业务中,直接使用本地IP进行大规模访问,可能带来合规和安全隐患。通过代理服务器转发请求,可以减少被追踪的可能性。如果结合HTTPS代理使用,还能在数据传输过程中提供额外的加密保护。
在选择HTTP代理时,应根据业务规模和目标网站特性进行判断。共享代理成本较低,但稳定性和安全性相对有限;专用代理独占IP资源,更适合对成功率要求较高的项目;旋转代理则通过自动更换IP,提高高频抓取场景下的可用性。同时,代理的速度、稳定性和服务支持能力,都会直接影响爬虫效率。
在实际应用中,HTTP代理已广泛用于电商价格监测、社交媒体数据分析、金融信息抓取以及新闻舆情监控等场景。通过合理配置代理策略,可以在保障访问稳定性的同时,提高数据采集的覆盖面与时效性,为各类数据驱动型业务提供可靠支撑。
zhyun
暂无介绍....