.png)
爬虫数据采集与数据分析的关系解析:从数据获取到价值挖掘

在数据驱动决策成为主流的背景下,爬虫数据采集与数据分析已经成为数据科学和信息技术领域中不可分割的两个环节。前者解决“数据从哪里来”的问题,后者关注“数据能说明什么”。二者相互配合,共同构成完整的数据处理与价值转化链路。
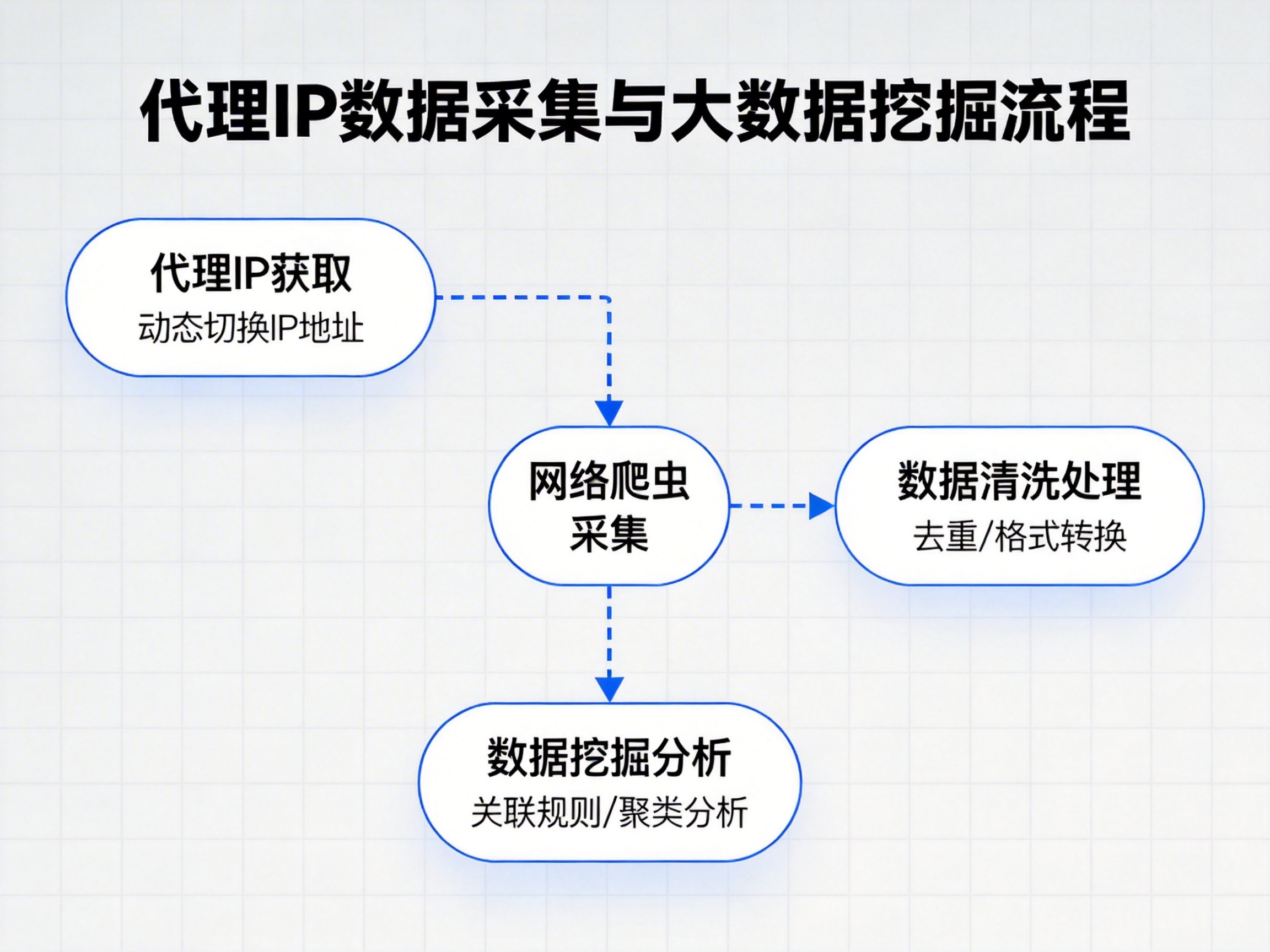
首先,从数据来源角度来看,爬虫数据采集是数据分析的重要基础。爬虫技术通过模拟用户访问行为,从各类网站、接口或公开平台中获取数据内容,包括文本、图片、价格信息、评论数据等。这些数据往往分散在不同站点中,人工获取成本高、效率低,而爬虫能够实现自动化、规模化采集。数据分析则以这些采集到的数据作为输入,对其进行整理和解读,从而提炼出有价值的信息。
其次,在数据准备阶段,两者之间的衔接尤为紧密。爬虫采集到的数据通常是原始状态,存在格式不统一、字段缺失、内容冗余等问题。只有经过清洗、标准化和结构化处理,数据才能进入分析阶段。数据分析工作对数据质量要求较高,这也反向推动爬虫在采集时更加注重规则设计,例如字段完整性、数据一致性以及重复数据控制。
再次,在特征工程层面,爬虫与数据分析形成了明显的协同关系。爬虫可以按照分析需求,有针对性地抓取特定字段或页面结构,为后续特征构建提供素材。数据分析人员则会根据业务目标,对采集到的数据进行筛选、组合和转换,形成对模型或分析结果更有价值的特征变量。这一过程往往需要不断调整采集策略,以匹配分析需求的变化。
从建模与算法应用来看,爬虫本身并不参与模型构建,但它直接决定了模型训练数据的广度和深度。数据分析阶段会根据业务场景选择统计分析、机器学习或深度学习算法,而这些算法的效果,很大程度上依赖于爬虫采集数据的数量、时效性和多样性。例如,在市场趋势分析或舆情监测中,持续稳定的数据采集是模型有效运行的前提。
在模型验证和优化过程中,数据质量的重要性更加凸显。如果爬虫采集的数据存在偏差或噪声较多,分析结果就可能失真。数据分析人员在验证模型时,往往会发现数据层面的问题,并据此调整采集频率、采集范围或过滤规则,从而提高整体分析效果。
最后,两者之间还存在明显的反馈机制。数据分析得到的结论,可能会揭示新的关注点或业务方向,从而促使爬虫增加新的采集目标或调整数据结构。爬虫采集的持续优化,又能为数据分析提供更贴合需求的数据支持。这种循环不断推进数据价值的深化。
整体来看,爬虫数据采集负责构建数据基础,数据分析负责释放数据价值。二者相互依赖、相互促进,共同支撑起从信息获取到决策支持的完整流程,是现代数据应用体系中不可或缺的重要组成部分。
zhyun
暂无介绍....