.png)
新手入门Python爬虫需要掌握哪些基础知识

随着数据价值不断提升,Python爬虫已成为数据采集领域中应用广泛的技术之一。对于刚接触爬虫的新手而言,盲目上手往往事倍功半,提前打好基础不仅能降低学习难度,也有助于后续项目的稳定推进。下面从多个方面,对学习Python爬虫前应掌握的核心知识进行系统梳理。
首先是Python语言本身的基础能力。学习爬虫前,应熟悉Python的基本语法规则,包括变量定义、条件判断、循环结构等内容。同时,需要掌握常见的数据类型和数据结构,如字符串、列表、字典、元组等,并理解它们在数据处理中的使用场景。此外,函数的定义、调用以及参数传递方式,也是后续编写爬虫逻辑不可或缺的部分。
其次是对网页结构的基本理解。爬虫本质上是从网页中提取数据,因此需要具备一定的HTML和CSS基础。了解HTML标签结构、层级关系以及常见属性,有助于快速定位页面中的目标数据。CSS方面不需要深入样式设计,但应了解选择器的基本用法,为后续数据解析打下基础。
在网络层面,HTTP协议相关知识同样重要。需要了解HTTP请求与响应的基本流程,常见的请求方法如GET和POST,以及状态码所代表的含义。这些知识可以帮助新手更好地理解数据请求失败或返回异常的原因,提高排错效率。
正则表达式也是爬虫学习过程中常用的工具之一。通过正则表达式,可以对文本内容进行灵活匹配和提取,尤其在处理非标准化页面数据时,具有一定实用价值。虽然在实际项目中常与解析库配合使用,但掌握其基本规则依然十分必要。
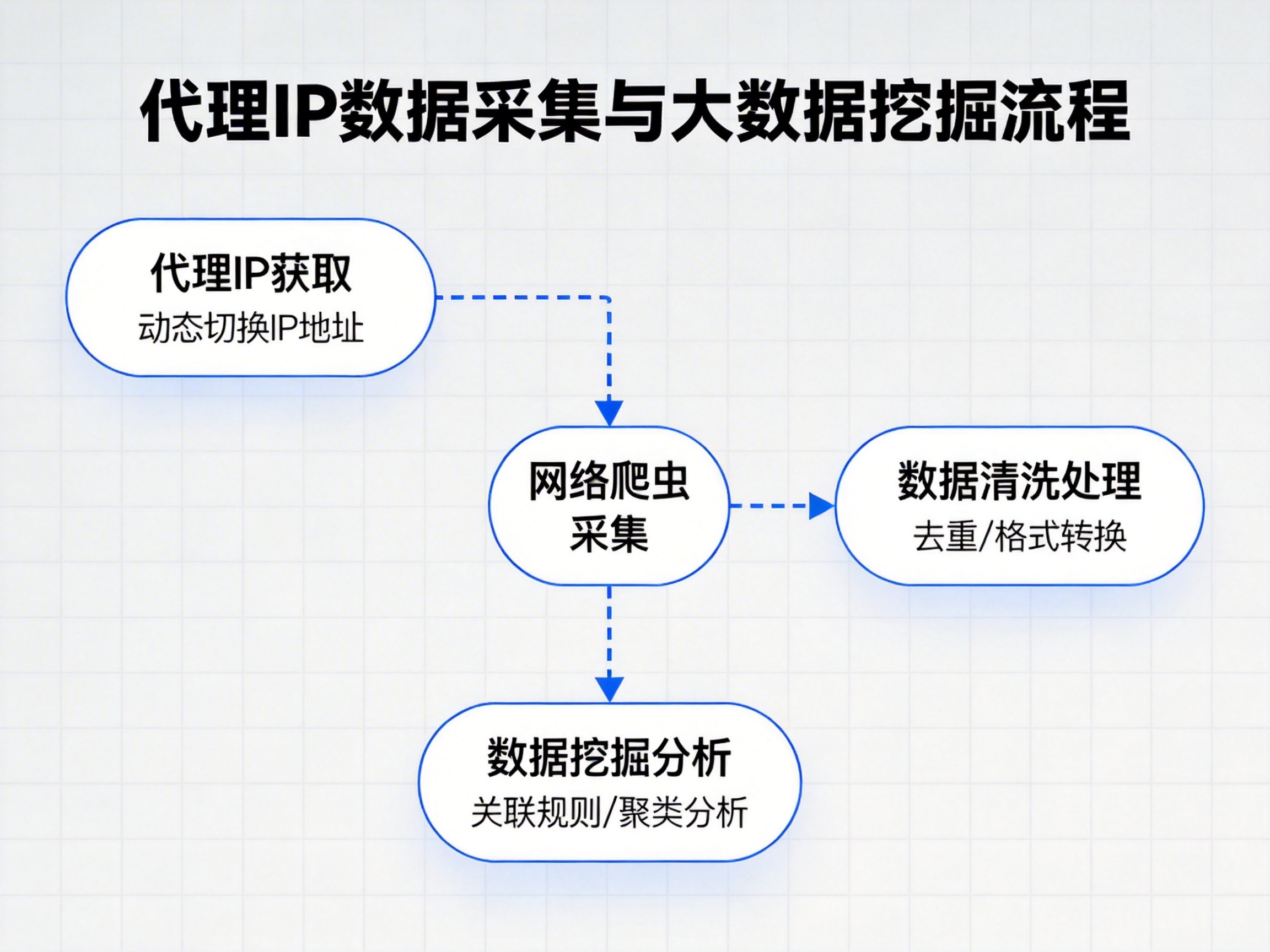
在实际操作层面,需要熟悉Python中常用的网络请求方式,例如使用requests库发送HTTP请求,并对返回结果进行处理。理解响应内容中的文本、编码和状态信息,有助于更准确地获取有效数据。
在数据解析方面,XPath和CSS选择器是爬虫中使用频率较高的技术。通过这些规则,可以从HTML文档中精准提取所需内容。配合BeautifulSoup和lxml等解析库,能够显著提升爬虫开发效率和代码可读性。
当爬虫需求逐步复杂时,了解Scrapy框架将非常有帮助。Scrapy作为成熟的爬虫框架,集成了请求调度、数据处理和异常管理等功能,适合中大型采集项目的开发与维护。
数据存储同样是爬虫流程的重要一环。新手需要掌握基础的文件读写操作,以及常见数据库的基本概念。通过Python将采集到的数据保存到本地文件或数据库中,才能形成完整的数据链路。
此外,还应对常见的反爬虫机制有所了解,例如验证码校验、访问频率限制、IP封禁等。这有助于在实际项目中合理规划采集策略,避免无效请求和资源浪费。
最后,爬虫的合规性问题不容忽视。学习过程中应了解robots.txt规则,控制访问频率,尊重网站的使用规范,确保数据采集行为在合法、合理的范围内进行。这不仅是技术问题,也是长期从业中必须遵守的基本原则。
整体来看,Python爬虫并非单一技术点,而是多项基础能力的综合应用。新手在学习过程中循序渐进,逐步补齐上述知识体系,更有利于后续在数据采集与分析领域的深入实践。
zhyun
暂无介绍....